


An essential and controversial subject within the space of private pockets safety is the idea of “brainwallets” – storing funds utilizing a non-public key generated from a password memorized solely in a single’s head. Theoretically, brainwallets have the potential to offer virtually utopian assure of safety for long-term financial savings: for so long as they’re saved unused, they aren’t weak to bodily theft or hacks of any type, and there’s no method to even show that you just nonetheless keep in mind the pockets; they’re as protected as your very personal human thoughts. On the similar time, nonetheless, many have argued in opposition to the usage of brainwallets, claiming that the human thoughts is fragile and never properly designed for producing, or remembering, lengthy and fragile cryptographic secrets and techniques, and so they’re too harmful to work in actuality. Which facet is correct? Is our reminiscence sufficiently sturdy to guard our non-public keys, is it too weak, or is maybe a 3rd and extra fascinating chance really the case: that all of it depends upon how the brainwallets are produced?
Entropy
If the problem at hand is to create a brainwallet that’s concurrently memorable and safe, then there are two variables that we have to fear about: how a lot data we’ve got to recollect, and the way lengthy the password takes for an attacker to crack. Because it seems, the problem in the issue lies in the truth that the 2 variables are very extremely correlated; the truth is, absent a couple of sure particular sorts of particular methods and assuming an attacker operating an optimum algorithm, they’re exactly equal (or fairly, one is exactly exponential within the different). Nevertheless, to start out off we will deal with the 2 sides of the issue individually.
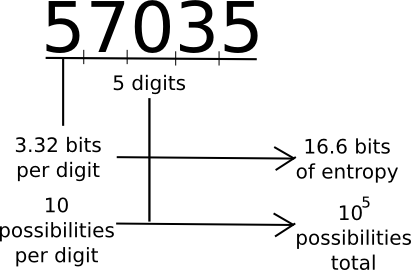
A standard measure that pc scientists, cryptogaphers and mathematicians use to measure “how a lot data” a chunk of knowledge comprises is “entropy”. Loosely outlined, entropy is outlined because the logarithm of the variety of doable messages which are of the identical “type” as a given message. For instance, take into account the quantity 57035. 57035 appears to be within the class of five-digit numbers, of which there are 100000. Therefore, the quantity comprises about 16.6 bits of entropy, as 216.6 ~= 100000. The quantity 61724671282457125412459172541251277 is 35 digits lengthy, and log(1035) ~= 116.3, so it has 116.3 bits of entropy. A random string of ones and zeroes n bits lengthy will include precisely n bits of entropy. Thus, longer strings have extra entropy, and strings which have extra symbols to select from have extra entropy.
Then again, the quantity 11111111111111111111111111234567890 has a lot lower than 116.3 bits of entropy; though it has 35 digits, the quantity shouldn’t be of the class of 35-digit numbers, it’s within the class of 35-digit numbers with a really excessive degree of construction; a whole record of numbers with at the least that degree of construction could be at most a couple of billion entries lengthy, giving it maybe solely 30 bits of entropy.
Info concept has plenty of extra formal definitions that attempt to grasp this intuitive idea. A very widespread one is the thought of Kolmogorov complexity; the Kolmogorov complexity of a string is principally the size of the shortest pc program that can print that worth. In Python, the above string can be expressible as ‘1’*26+’234567890′ – an 18-character string, whereas 61724671282457125412459172541251277 takes 37 characters (the precise digits plus quotes). This offers us a extra formal understanding of the thought of “class of strings with excessive construction” – these strings are merely the set of strings that take a small quantity of knowledge to specific. Observe that there are different compression methods we will use; for instance, unbalanced strings like 1112111111112211111111111111111112111 could be minimize by at the least half by creating particular symbols that characterize a number of 1s in sequence. Huffman coding is an instance of an information-theoretically optimum algorithm for creating such transformations.
Lastly, be aware that entropy is context-dependent. The string “the fast brown fox jumped over the lazy canine” could have over 100 bytes of entropy as a easy Huffman-coded sequence of characters, however as a result of we all know English, and since so many 1000’s of knowledge concept articles and papers have already used that actual phrase, the precise entropy is maybe round 25 bytes – I would confer with it as “fox canine phrase” and utilizing Google you possibly can work out what it’s.
So what’s the level of entropy? Primarily, entropy is how a lot data it’s important to memorize. The extra entropy it has, the tougher to memorize it’s. Thus, at first look it appears that you really want passwords which are as low-entropy as doable, whereas on the similar time being exhausting to crack. Nevertheless, as we’ll see under this mind-set is fairly harmful.
Power
Now, allow us to get to the following level, password safety in opposition to attackers. The safety of a password is greatest measured by the anticipated variety of computational steps that it could take for an attacker to guess your password. For randomly generated passwords, the best algorithm to make use of is brute power: strive all doable one-character passwords, then all two-character passwords, and so forth. Given an alphabet of n characters and a password of size ok, such an algorithm would crack the password in roughly nok time. Therefore, the extra characters you employ, the higher, and the longer your password is, the higher.
There’s one strategy that tries to elegantly mix these two methods with out being too exhausting to memorize: Steve Gibson’s haystack passwords. As Steve Gibson explains:
Which of the next two passwords is stronger, safer, and harder to crack?
You most likely know it is a trick query, however the reply is: Even if the primary password is HUGELY simpler to make use of and extra memorable, it is usually the stronger of the 2! In actual fact, since it’s one character longer and comprises uppercase, lowercase, a quantity and particular characters, that first password would take an attacker roughly 95 occasions longer to search out by looking than the second impossible-to-remember-or-type password!
Steve then goes on to write down: “Just about everybody has all the time believed or been instructed that passwords derived their energy from having “excessive entropy”. However as we see now, when the one out there assault is guessing, that long-standing frequent knowledge . . . is . . . not . . . appropriate!” Nevertheless, as seductive as such a loophole is, sadly on this regard he’s lifeless unsuitable. The reason being that it depends on particular properties of assaults which are generally in use, and if it turns into extensively used assaults might simply emerge which are specialised in opposition to it. In actual fact, there’s a generalized assault that, given sufficient leaked password samples, can mechanically replace itself to deal with virtually something: Markov chain samplers.
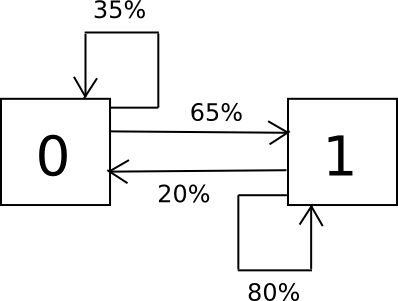
The way in which the algorithm works is as follows. Suppose that the alphabet that you’ve got consists solely of the characters 0 and 1, and you realize from sampling {that a} 0 is adopted by a 1 65% of the time and a 0 35% of the time, and a 1 is adopted by a 0 20% of the time and a 1 80% of the time. To randomly pattern the set, we create a finite state machine containing these possibilities, and easily run it time and again in a loop.
Here is the Python code:
import random i = 0 whereas 1: if i == 0: i = 0 if random.randrange(100) < 35 else 1 elif i == 1: i = 0 if random.randrange(100) < 20 else 1 print i
We take the output, break it up into items, and there we’ve got a approach of producing passwords which have the identical sample as passwords that individuals really use. We are able to generalize this previous two characters to a whole alphabet, and we will even have the state hold monitor not simply of the final character however the final two, or three or extra. So if everybody begins making passwords like “D0g…………………”, then after seeing a couple of thousand examples the Markov chain will “be taught” that individuals usually make lengthy strings of intervals, and if it spits out a interval it would usually get itself briefly caught in a loop of printing out extra intervals for a couple of steps – probabilistically replicating individuals’s conduct.
The one half that was unnoticed is terminate the loop; as given, the code merely offers an infinite string of zeroes and ones. We might introduce a pseudo-symbol into our alphabet to characterize the top of a string, and incorporate the noticed charge of occurrences of that image into our Markov chain possibilities, however that is not optimum for this use case – as a result of much more passwords are brief than lengthy, it could often output passwords which are very brief, and so it could repeat the brief passwords thousands and thousands of occasions earlier than making an attempt a lot of the lengthy ones. Thus we’d need to artificially minimize it off at some size, and enhance that size over time, though extra superior methods additionally exist like operating a simultaneous Markov chain backwards. This common class of methodology is often known as a “language mannequin” – a likelihood distribution over sequences of characters or phrases which could be as easy and tough or as advanced and complicated as wanted, and which may then be sampled.
The elemental purpose why the Gibson technique fails, and why no different technique of that sort can probably work, is that within the definitions of entropy and energy there may be an fascinating equivalence: entropy is the logarithm of the variety of potentialities, however energy is the variety of potentialities – briefly, memorizability and attackability are invariably precisely the identical! This is applicable no matter whether or not you’re randomly choosing characters from an alphabet, phrases from a dictionary, characters from a biased alphabet (eg. “1” 80% of the time and “0” 20% of the time, or strings that comply with a specific sample). Thus, it appears that evidently the search for a safe and memorizable password is hopeless…
Easing Reminiscence, Hardening Assaults
… or not. Though the essential concept that entropy that must be memorized and the house that an attacker must burn by are precisely the identical is mathematically and computationally appropriate, the issue lives in the actual world, and in the actual world there are a selection of complexities that we will exploit to shift the equation to our benefit.
The primary essential level is that human reminiscence shouldn’t be a computer-like retailer of knowledge; the extent to which you’ll be able to precisely keep in mind data usually depends upon the way you memorize it, and in what format you retailer it. For instance, we implicitly memorize kilobytes of knowledge pretty simply within the type of human faces, however even one thing as comparable within the grand scheme of issues as canine faces are a lot tougher for us. Info within the type of textual content is even tougher – though if we memorize the textual content visually and orally on the similar time it is considerably simpler once more.
Some have tried to benefit from this truth by producing random brainwallets and encoding them in a sequence of phrases; for instance, one would possibly see one thing like:
witch collapse follow feed disgrace open despair creek highway once more ice least
A widespread XKCD comedian illustrates the precept, suggesting that customers create passwords by producing 4 random phrases as an alternative of making an attempt to be intelligent with image manipulation. The strategy appears elegant, and maybe taking away of our differing capability to recollect random symbols and language on this approach, it simply would possibly work. Besides, there’s an issue: it does not.
To cite a current research by Richard Shay and others from Carnegie Mellon:
In a 1,476-participant on-line research, we explored the usability of 3- and 4-word system- assigned passphrases compared to system-assigned passwords composed of 5 to six random characters, and 8-character system-assigned pronounceable passwords. Opposite to expectations, sys- tem-assigned passphrases carried out equally to system-assigned passwords of comparable entropy throughout the usability metrics we ex- amined. Passphrases and passwords have been forgotten at comparable charges, led to comparable ranges of person issue and annoyance, and have been each written down by a majority of contributors. Nevertheless, passphrases took considerably longer for contributors to enter, and seem to require error-correction to counteract entry errors. Passphrase usability didn’t appear to extend after we shrunk the dictionary from which phrases have been chosen, decreased the variety of phrases in a passphrase, or allowed customers to alter the order of phrases.
Nevertheless, the paper does depart off on a be aware of hope. It does be aware that there are methods to make passwords which are greater entropy, and thus greater safety, whereas nonetheless being simply as simple to memorize; randomly generated however pronounceable strings like “zelactudet” (presumably created through some type of per-character language mannequin sampling) appear to offer a average acquire over each phrase lists and randomly generated character strings. A possible reason behind that is that pronounceable passwords are more likely to be memorized each as a sound and as a sequence of letters, growing redundancy. Thus, we’ve got at the least one technique for enhancing memorizability with out sacrificing energy.
The opposite technique is to assault the issue from the alternative finish: make it tougher to crack the password with out growing entropy. We can not make the password tougher to crack by including extra combos, as that will enhance entropy, however what we will do is use what is named a tough key derivation operate. For instance, suppose that if our memorized brainwallet is b, as an alternative of creating the non-public key sha256(b) or sha3(b), we make it F(b, 1000) the place F is outlined as follows:
def F(b, rounds): x = b i = 0 whereas i < rounds: x = sha3(x + b) i += 1 return x
Primarily, we hold feeding b into the hash operate time and again, and solely after 1000 rounds will we take the output.

Feeding the unique enter again into every spherical shouldn’t be strictly crucial, however cryptographers advocate it with a purpose to restrict the impact of assaults involving precomputed rainbow tables. Now, checking every particular person password takes a thousand time longer. You, because the professional person, will not discover the distinction – it is 20 milliseconds as an alternative of 20 microseconds – however in opposition to attackers you get ten bits of entropy without cost, with out having to memorize something extra. If you happen to go as much as 30000 rounds you get fifteen bits of entropy, however then calculating the password takes near a second; 20 bits takes 20 seconds, and past about 23 it turns into too lengthy to be sensible.
Now, there may be one intelligent approach we will go even additional: outsourceable ultra-expensive KDFs. The thought is to give you a operate which is extraordinarily costly to compute (eg. 240 computational steps), however which could be computed indirectly with out giving the entity computing the operate entry to the output. The cleanest, however most cryptographically difficult, approach of doing that is to have a operate which may someway be “blinded” so unblind(F(blind(x))) = F(x) and blinding and unblinding requires a one-time randomly generated secret. You then calculate blind(password), and ship the work off to a 3rd celebration, ideally with an ASIC, after which unblind the response while you obtain it.
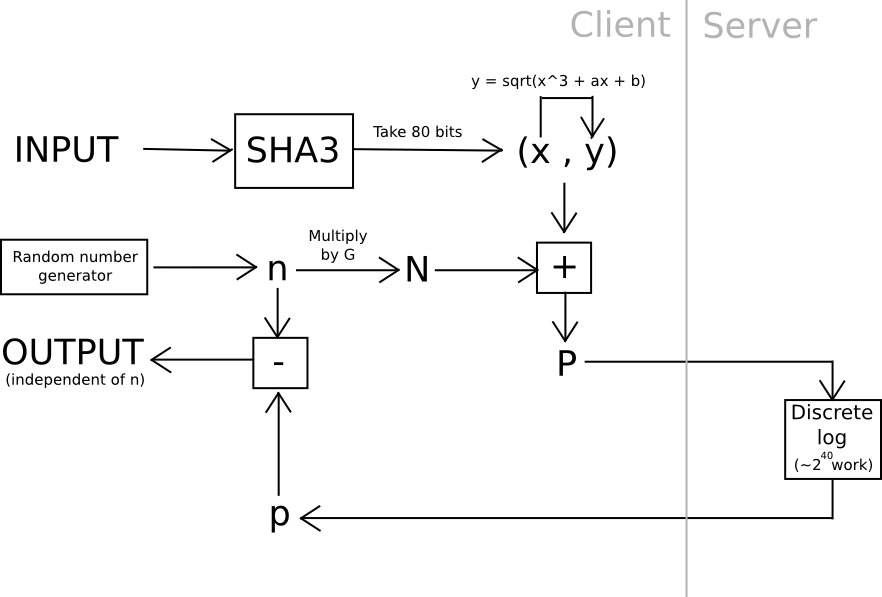
One instance of that is utilizing elliptic curve cryptography: generate a weak curve the place the values are solely 80 bits lengthy as an alternative of 256, and make the exhausting downside a discrete logarithm computation. That’s, we calculate a worth x by taking the hash of a worth, discover the related y on the curve, then we “blind” the (x,y) level by including one other randomly generated level, N (whose related non-public key we all know to be n), after which ship the consequence off to a server to crack. As soon as the server comes up with the non-public key similar to N + (x,y), we subtract n, and we get the non-public key similar to (x,y) – our meant consequence. The server doesn’t be taught any details about what this worth, and even (x,y), is – theoretically it may very well be something with the suitable blinding issue N. Additionally, be aware that the person can immediately confirm the work – merely convert the non-public key you get again into a degree, and make it possible for the purpose is definitely (x,y).
One other strategy depends considerably much less on algebraic options of nonstandard and intentionally weak elliptic curves: use hashes to derive 20 seeds from a password, apply a really exhausting proof of labor downside to every one (eg. calculate f(h) = n the place n is such that sha3(n+h) < 2^216), and mix the values utilizing a reasonably exhausting KDF on the finish. Except all 20 servers collude (which could be prevented if the person connects by Tor, since it could be unattainable even for an attacker controlling or seeing the outcomes of 100% of the community to find out which requests are coming from the identical person), the protocol is safe.
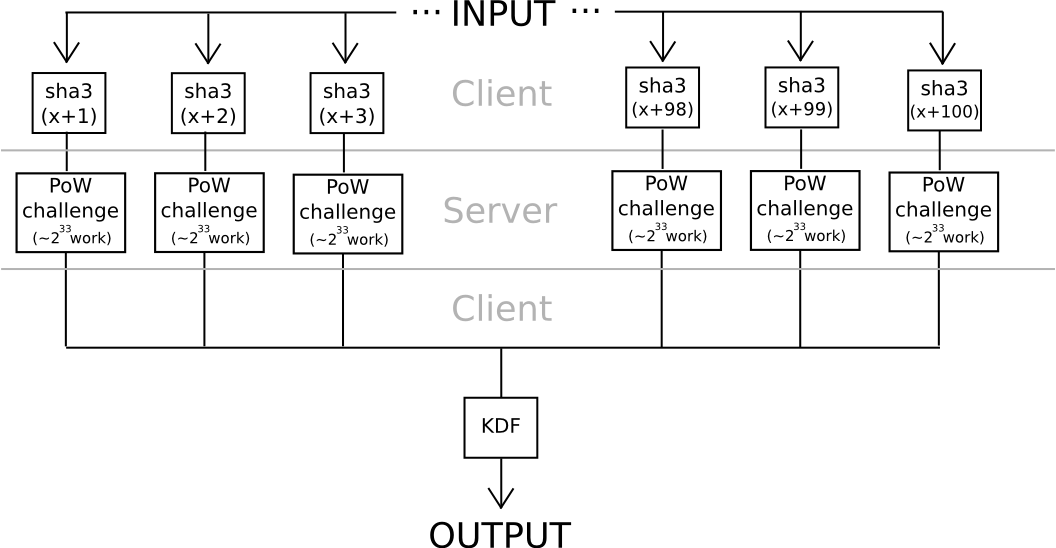
The fascinating factor about each of those protocols is that they’re pretty simple to show right into a “helpful proof of labor” consensus algorithm for a blockchain; anybody might submit work for the chain to course of, the chain would carry out the computations, and each elliptic curve discrete logs and hash-based proofs of labor are very simple to confirm. The elegant a part of the scheme is that it turns to social use each customers’ bills in computing the work operate, but in addition attackers’ a lot higher bills. If the blockchain backed the proof of labor, then it could be optimum for attackers to additionally attempt to crack customers’ passwords by submitting work to the blockchain, through which case the attackers would contribute to the consensus safety within the course of. However then, in actuality at this degree of safety, the place 240 work is required to compute a single password, brainwallets and different passwords could be so safe that nobody would even hassle attacking them.
Entropy Differentials
Now, we get to our ultimate, and most fascinating, memorization technique. From what we mentioned above, we all know that entropy, the quantity of knowledge in a message, and the complexity of assault are precisely equivalent – until you make the method intentionally slower with costly KDFs. Nevertheless, there may be one other level about entropy that was talked about in passing, and which is definitely essential: skilled entropy is context-dependent. The identify “Mahmoud Ahmadjinejad” may need maybe ten to fifteen bits of entropy to us, however to somebody dwelling in Iran whereas he was president it may need solely 4 bits – within the record of an important individuals of their lives, he’s fairly probably within the prime sixteen. Your dad and mom or partner are fully unknown to myself, and so for me their names have maybe twenty bits of entropy, however to you they’ve solely two or three bits.
Why does this occur? Formally, one of the simplest ways to consider it’s that for every individual the prior experiences of their lives create a type of compression algorithm, and underneath completely different compression algorithms, or completely different programming languages, the identical string can have a distinct Kolmogorov complexity. In Python, ‘111111111111111111’ is simply ‘1’*18, however in Javascript it is Array(19).be a part of(“1”). In a hypothetical model of Python with the variable x preset to ‘111111111111111111’, it is simply x. The final instance, though seemingly contrived, is definitely the one which greatest describes a lot of the actual world; the human thoughts is a machine with many variables preset by our previous experiences.
This fairly easy perception results in a very elegant technique for password memorizability: attempt to create a password the place the “entropy differential”, the distinction between the entropy to you and the entropy to different individuals, is as giant as doable. One easy technique is to prepend your personal username to the password. If my password have been to be “yui&(4_”, I would do “vbuterin:yui&(4_” as an alternative. My username may need about ten to fifteen bits of entropy to the remainder of the world, however to me it is virtually a single bit. That is primarily the first purpose why usernames exist as an account safety mechanism alongside passwords even in instances the place the idea of customers having “names” shouldn’t be strictly crucial.
Now, we will go a bit additional. One frequent piece of recommendation that’s now generally and universally derided as nugatory is to choose a password by taking a phrase out of a e-book or music. The explanation why this concept is seductive is as a result of it appears to cleverly exploit differentials: the phrase may need over 100 bits of entropy, however you solely want to recollect the e-book and the web page and line quantity. The issue is, after all, that everybody else has entry to the books as properly, and so they can merely do a brute power assault over all books, songs and flicks utilizing that data.
Nevertheless, the recommendation shouldn’t be nugatory; the truth is, if used as solely half of your password, a quote from a e-book, music or film is a superb ingredient. Why? Easy: it creates a differential. Your favourite line out of your favourite music solely has a couple of bits of entropy to you, but it surely’s not everybody’s favourite music, so to your complete world it may need ten or twenty bits of entropy. The optimum technique is thus to choose a e-book or music that you just actually like, however which can be maximally obscure – push your entropy down, and others’ entropy greater. After which, after all, prepend your username and append some random characters (even perhaps a random pronounceable “phrase” like “zelactudet”), and use a safe KDF.
Conclusion
How a lot entropy do that you must be safe? Proper now, password cracking chips can carry out about 236 makes an attempt per second, and Bitcoin miners can carry out roughly 240 hashes per second (that is 1 terahash). The complete Bitcoin community collectively does 250 petahashes, or about 257 hashes per second. Cryptographers usually take into account 280 to be an appropriate minimal degree of safety. To get 80 bits of entropy, you want both about 17 random letters of the alphabet, or 12 random letters, numbers and symbols. Nevertheless, we will shave fairly a bit off the requirement: fifteen bits for a username, fifteen bits for KDF, maybe ten bits for an abbreviation from a passage from a semi-obscure music or e-book that you just like, after which 40 extra bits of plan previous easy randomness. If you happen to’re not utilizing KDF, then be happy to make use of different components.
It has turn into fairly widespread amongst safety consultants to dismiss passwords as being essentially insecure, and argue for password schemes to get replaced outright. A standard argument is that due to Moore’s regulation attackers’ energy will increase by one little bit of entropy each two years, so you’ll have to carry on memorizing increasingly more to stay safe. Nevertheless, this isn’t fairly appropriate. If you happen to use a tough KDF, Moore’s regulation permits you to take away bits from the attacker’s energy simply as shortly because the attacker features energy, and the truth that schemes resembling these described above, aside from KDFs (the average type, not the outsourceable type), haven’t even been tried suggests that there’s nonetheless some method to go. On the entire, passwords thus stay as safe as they’ve ever been, and stay very helpful as one ingredient of a robust safety coverage – simply not the one ingredient. Reasonable approaches that use a mix of {hardware} wallets, trusted third events and brainwallets could even be what wins out in the long run.
